What is the principal component method based on? Principal component analysis (mc): basic formulas and procedures

 Live Journal
Live Journal Facebook
Facebook Twitter
TwitterPrincipal component method or component analysis Principal component analysis (PCA) is one of the most important methods in the arsenal of a zoologist or ecologist. Unfortunately, in those cases when it is quite appropriate to use component analysis, cluster analysis is often used.
A typical task for which component analysis is useful is as follows: there is a certain set of objects, each of which is characterized by a certain (sufficiently large) number of features. The researcher is interested in the patterns reflected in the diversity of these objects. In the case when there is reason to assume that objects are distributed into hierarchically subordinate groups, you can use cluster analysis - the method classification (distribution by group). If there is no reason to expect that the variety of objects reflects some kind of hierarchy, it is logical to use ordination (ordered arrangement). If each object is characterized by a sufficiently large number of features (at least, such a number of features that cannot be adequately reflected on one graph), it is optimal to start data research with the analysis of the principal components. The fact is that this method is at the same time a method of decreasing the dimension (number of measurements) of data.
If the group of objects under consideration is characterized by the values \u200b\u200bof one feature, to characterize their diversity, you can use a histogram (for continuous features) or a bar chart (to characterize the frequencies of a discrete feature). If the objects are characterized by two features, you can use a two-dimensional scatter plot, if three - three-dimensional. And if there are many signs? You can try on a two-dimensional graph to reflect the relative position of objects relative to each other in multidimensional space. Usually, such a decrease in dimension is associated with the loss of information. Of the various possible methods of such a display, one must choose the one in which the loss of information will be minimal.
Let us explain what has been said using the simplest example: the transition from two-dimensional space to one-dimensional. The minimum number of points that a two-dimensional space (plane) defines is 3. In fig. 9.1.1 shows the location of three points on the plane. The coordinates of these points are easy to read from the drawing itself. How to choose a straight line that will carry the maximum information about the relative position of points?
Figure: 9.1.1. Three points on a plane defined by two features. On which line will the maximum dispersion of these points be projected?
Consider the projection of points onto line A (shown in blue). The coordinates of the projections of these points on the line A are as follows: 2, 8, 10. The average value is 6 2/3. Dispersion (2-6 2/3) + (8-6 2/3) + (10-6 2/3) \u003d 34 2/3.
Now consider line B (shown in green). Point coordinates - 2, 3, 7; the mean is 4, the variance is 14. Thus, line B reflects a smaller proportion of the variance than line A.
What is this share? Since lines A and B are orthogonal (perpendicular), the proportions of the total variance projected onto A and B do not intersect. This means that the total variance of the location of the points of interest to us can be calculated as the sum of these two terms: 34 2/3 + 14 \u003d 48 2/3. At the same time, 71.2% of the total variance is projected onto line A, and 28.8% - on line B.
How to determine which line will be affected by the maximum share of variance? This line will correspond to the regression line for the points of interest, which is denoted as C (red). This line will reflect 77.2% of the total variance, and this is the maximum possible value for a given location of points. Such a straight line on which the maximum fraction of the total variance is projected is called the first main component.
What is the direct line to reflect the remaining 22.8% of the total variance? On a straight line perpendicular to the first main component. This straight line will also be the main component, because the maximum possible proportion of the variance will be reflected on it (naturally, without taking into account the one that affected the first main component). So it is - second main component.
Calculating these principal components using Statistica (we will describe the dialogue a little later), we get the picture shown in Fig. 9.1.2. The coordinates of points on the principal components are shown in standard deviations.
Figure: 9.1.2. The location of the three points shown in Fig. 9.1.1, on the plane of the two principal components. Why are these points located in relation to each other differently than in Fig. 9.1.1?
In fig. 9.1.2 the relative position of the points is changed. In order to correctly interpret such pictures in the future, one should consider the reasons for the differences in the location of the points in Fig. 1 and 9.1.2 for details. Point 1 in both cases is to the right (has a larger coordinate in the first attribute and the first main component) than point 2. But, for some reason, point 3 at the original location is below the other two points (has the smallest attribute value 2), and above two other points on the plane of the principal components (has a large coordinate along the second component). This is due to the fact that the principal component analysis optimizes the variance of the initial data projected on the axes it chooses. If the main component is correlated with some original axis, the component and axis can be directed in the same direction (have a positive correlation) or in opposite directions (have a negative correlation). Both of these options are equivalent. The principal component analysis algorithm can "flip" or not "flip" any plane; no conclusions should be drawn from this.
However, the points in Fig. 9.1.2 are not simply "upside down" compared to their relative positions in fig. 9.1.1; in a certain way, their relationship has also changed. The differences between the points along the second principal component appear to be enhanced. 22.76% of the total variance attributable to the second component "moved" the points by the same distance as 77.24% of the variance attributable to the first principal component.
In order for the location of points on the plane of the principal components to correspond to their actual location, this plane should be distorted. In fig. 9.1.3. two concentric circles are shown; their radii are correlated as a fraction of the variances reflected by the first and second principal components. The picture corresponding to Fig. 9.1.2 is distorted so that the standard deviation of the first principal component corresponds to the larger circle, and the second to the smaller one.

Figure: 9.1.3. We took into account that the first principal component has 6 abouta greater proportion of variance than the second. To do this, we distorted Fig. 9.1.2, fitting it under two concentric circles, the radii of which are related, as the proportion of variances attributable to the main components. But the location of the points still does not correspond to the original one shown in Fig. 9.1.1!
Why is the relative position of the points in Fig. 9.1.3 does not correspond to the one in fig. 9.1.1? In the original figure, fig. 9.1 points are located in accordance with their coordinates, and not in accordance with the proportion of variance falling on each axis. A distance of 1 unit according to the first feature (along the abscissa) in Fig. 1, there is a smaller proportion of the variance of points along this axis than a distance of 1 unit according to the second feature (along the ordinate). And in Figure 9.1.1, the distances between the points are determined by the very units in which the features are measured by which they are described.
Let's complicate the task a little. Table 9.1.1 shows the coordinates of 10 points in 10-dimensional space. The first three points and the first two dimensions are the example we just looked at.
Table 9.1.1. Point coordinates for further analysis
|
Coordinates |
||||||||||
For educational purposes, first we will consider only part of the data from Table. 9.1.1. In fig. 9.1.4 we see the position of ten points on the plane of the first two features. Note that the first main component (line C) went slightly differently than in the previous case. No wonder: all points in question influence its position.

Figure: 9.1.4. We have increased the number of points. The first main component is already proceeding somewhat differently, because it was influenced by the added points
In fig. 9.1.5 shows the position of the 10 points we have considered on the plane of the first two components. Note: everything has changed, not only the proportion of variance attributable to each principal component, but even the position of the first three points!

Figure: 9.1.5. Ordination in the plane of the first principal components of 10 points, described in table. 9.1.1. Only the values \u200b\u200bof the first two features were considered, the last 8 columns of Table. 9.1.1 not used
In general, this is natural: since the main components are located differently, the relative position of the points has also changed.
Difficulties in comparing the location of points on the plane of the principal components and on the initial plane of the values \u200b\u200bof their features may cause confusion: why use such a difficult-to-interpret method? The answer is simple. In the event that the objects being compared are described by only two features, it is quite possible to use their ordination by these initial features. All the advantages of the principal component analysis appear in the case of multivariate data. Principal component analysis turns out to be an effective way to reduce the dimension of the data.
9.2. Go to initial data with a large number of dimensions
Let's consider a more complex case: let's analyze the data presented in table. 9.1.1 for all ten criteria. In fig. 9.2.1 shows how the window of the method of interest to us is called.

Figure: 9.2.1. Run the Principal Component Method
We will only be interested in the choice of features for analysis, although the Statistica dialog allows much more fine tuning (Fig. 9.2.2).

Figure: 9.2.2. Selecting Variables for Analysis
After the analysis is completed, a window of its results appears with several tabs (Fig. 9.2.3). All main windows are available from the first tab.

Figure: 9.2.3. The first tab of the Principal Component Analysis Results dialog
You can see that the analysis identified 9 main components, and described using them 100% of the variance reflected in 10 initial features. This means that one feature was redundant, redundant.
Let's start looking at the results with the "Plot case factor voordinates, 2D" button: it will show the location of the points on the plane defined by the two main components. By clicking this button, we will get into a dialog where we will need to specify which components we will use; it is natural to start the analysis with the first and second components. The result is shown in Fig. 9.2.4.

Figure: 9.2.4. Ordination of the considered objects on the plane of the first two principal components
The position of the points has changed, and this is natural: new features are involved in the analysis. In fig. 9.2.4 reflects more than 65% of the total diversity in the position of points relative to each other, and this is already a non-trivial result. For example, returning to table. 1, you can verify that points 4 and 7, as well as 8 and 10 are really close enough to each other. However, the differences between them may relate to other main components not shown in the figure: they, nevertheless, also account for a third of the remaining variability.
By the way, when analyzing the placement of points on the plane of the principal components, it may be necessary to analyze the distances between them. The easiest way to get a matrix of distances between points is using the cluster analysis module.
And how are the selected main components related to the original features? This can be found by clicking the button (Fig. 9.2.3) Plot var. factor coordinates, 2D. The result is shown in Fig. 9.2.5.

Figure: 9.2.5. Projections of the original features onto the plane of the first two principal components
We look at the plane of the two principal components "from above". The original features, which have nothing to do with the principal components, will be perpendicular (or almost perpendicular) to them and will be reflected in short lines ending near the origin. Thus, trait number 6 is least of all associated with the first two main components (although it demonstrates a certain positive correlation with the first component). Segments corresponding to those features that are fully reflected in the plane of the principal components will end on a circle of unit radius enclosing the center of the drawing.
For example, you can see that the first principal component was most strongly influenced by traits 10 (positively correlated) and 7 and 8 (negatively correlated). To examine the structure of such correlations in more detail, you can click the Factor coordinates of variables button, and get the table shown in Fig. 9.2.6.

Figure: 9.2.6. Correlations between the original features and the identified principal components (Factors)
The Eigenvalues \u200b\u200bbutton displays values \u200b\u200bthat are called eigenvalues \u200b\u200bof principal components... At the top of the window shown in Fig. 9.2.3, such values \u200b\u200bare derived for the first few components; the Scree plot button shows them in an easy-to-read form (Fig. 9.2.7).

Figure: 9.2.7. Eigenvalues \u200b\u200bof the selected principal components and the proportion of the total variance reflected by them
First, you need to understand what exactly the eigenvalue shows. It is a measure of the variance reflected in the main component, measured in the amount of variance attributable to each feature in the initial data. If the eigenvalue of the first principal component is 3.4, this means that it reflects more variance than three features from the initial set. The eigenvalues \u200b\u200bare linearly related to the proportion of the variance attributable to the main component, the only thing is that the sum of the eigenvalues \u200b\u200bis equal to the number of original features, and the sum of the proportions of variance is 100%.
And what does it mean that information on variability for 10 traits was reflected in 9 main components? That one of the initial indications was redundant did not add any new information. And so it was; in fig. 9.2.8 shows how the set of points was generated, shown in table. 9.1.1.
The data matrix is \u200b\u200bthe source for the analysis
dimensions  , the i-th row of which characterizes the i-th observation (object) for all k indicators
, the i-th row of which characterizes the i-th observation (object) for all k indicators  ... The initial data are normalized, for which the average values \u200b\u200bof the indicators are calculated
... The initial data are normalized, for which the average values \u200b\u200bof the indicators are calculated  , as well as the values \u200b\u200bof standard deviations
, as well as the values \u200b\u200bof standard deviations  ... Then the matrix of normalized values
... Then the matrix of normalized values

with elements 
The matrix of paired correlation coefficients is calculated:

The main diagonal of the matrix contains the unit elements  .
.
The component analysis model is built by presenting the original normalized data as a linear combination of the principal components:

where  - "weight", i.e. factor loading
- "weight", i.e. factor loading  th main component on
th main component on  th variable;
th variable;
 -value
-value  th main component for
th main component for  -th observation (object), where
-th observation (object), where  .
.
In matrix form, the model has the form

here  - matrix of principal components of dimension
- matrix of principal components of dimension  ,
,
 - matrix of factorial loads of the same dimension.
- matrix of factorial loads of the same dimension.
Matrix  describes
describes  observations in space
observations in space  main components. Moreover, the elements of the matrix
main components. Moreover, the elements of the matrix  are normalized, and the principal components are not correlated with each other. It follows that
are normalized, and the principal components are not correlated with each other. It follows that  where
where  - unit matrix of dimension
- unit matrix of dimension  .
.
Element  matrices
matrices  characterizes the tightness of the linear relationship between the original variable
characterizes the tightness of the linear relationship between the original variable  and the main component
and the main component  , therefore, takes the values
, therefore, takes the values  .
.
Correlation matrix  can be expressed in terms of factor loadings matrix
can be expressed in terms of factor loadings matrix  .
.
Units are located along the main diagonal of the correlation matrix and, by analogy with the covariance matrix, they represent the variances of the used  - features, but unlike the latter, due to normalization, these variances are equal to 1. The total variance of the entire system
- features, but unlike the latter, due to normalization, these variances are equal to 1. The total variance of the entire system  - features in the sample volume
- features in the sample volume  is equal to the sum of these units, i.e. is equal to the trace of the correlation matrix
is equal to the sum of these units, i.e. is equal to the trace of the correlation matrix  .
.
The correlation matrix can be converted to a diagonal matrix, that is, a matrix, all values \u200b\u200bof which, except for the diagonal ones, are equal to zero:
 ,
,
where  - a diagonal matrix, on the main diagonal of which there are eigenvalues
- a diagonal matrix, on the main diagonal of which there are eigenvalues  correlation matrix,
correlation matrix,  is a matrix whose columns are the eigenvectors of the correlation matrix
is a matrix whose columns are the eigenvectors of the correlation matrix  ... Since the matrix R is positive definite, i.e. its major minors are positive, then all eigenvalues
... Since the matrix R is positive definite, i.e. its major minors are positive, then all eigenvalues  for any
for any  .
.
Eigenvalues  are found as the roots of the characteristic equation
are found as the roots of the characteristic equation

Eigenvector  corresponding to the eigenvalue
corresponding to the eigenvalue  correlation matrix
correlation matrix  , is defined as a nonzero solution to the equation
, is defined as a nonzero solution to the equation

Normalized eigenvector  is equal
is equal

The vanishing of the off-diagonal terms means that the features become independent of each other ( 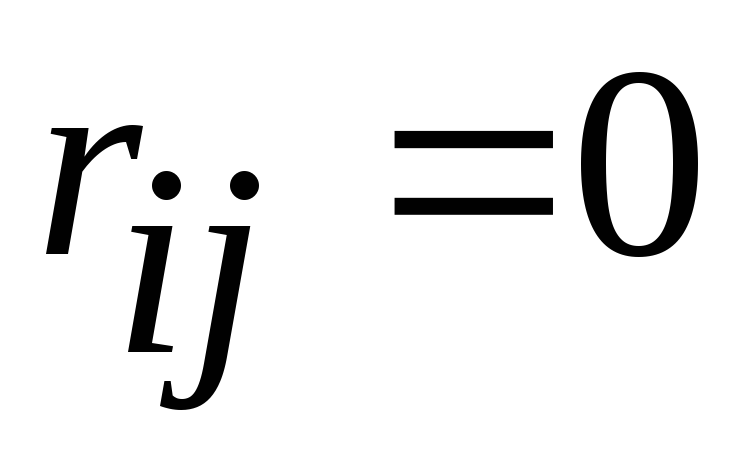 at
at  ).
).
Total variance of the entire system  variables in the sample remains the same. However, its values \u200b\u200bare redistributed. The procedure for finding the values \u200b\u200bof these variances is to find the eigenvalues
variables in the sample remains the same. However, its values \u200b\u200bare redistributed. The procedure for finding the values \u200b\u200bof these variances is to find the eigenvalues  correlation matrix for each of
correlation matrix for each of  - signs. The sum of these eigenvalues
- signs. The sum of these eigenvalues  is equal to the trace of the correlation matrix, i.e.
is equal to the trace of the correlation matrix, i.e.  , that is, the number of variables. These eigenvalues \u200b\u200bare the variance values \u200b\u200bof the features
, that is, the number of variables. These eigenvalues \u200b\u200bare the variance values \u200b\u200bof the features  in conditions if the signs were independent of each other.
in conditions if the signs were independent of each other.
In the method of principal components, the correlation matrix is \u200b\u200bfirst calculated from the initial data. Then, its orthogonal transformation is performed, and through this factor loadings are found  for all
for all  variables and
variables and  factors (factor load matrix), eigenvalues
factors (factor load matrix), eigenvalues  and determine the weights of the factors.
and determine the weights of the factors.
The factor loadings matrix A can be defined as  , and
, and  -th column of matrix A - as
-th column of matrix A - as  .
.
Weight of factors  or
or  reflects the share in the total variance introduced by this factor.
reflects the share in the total variance introduced by this factor.
Factor loadings vary from –1 to +1 and are analogous to the correlation coefficients. In the matrix of factor loads, it is necessary to select significant and insignificant loads using the Student's t test  .
.
Sum of squares of loads  th factor in all
th factor in all  - signs is equal to the eigenvalue of this factor
- signs is equal to the eigenvalue of this factor  ... Then
... Then  - the contribution of the i-th variable in% to the formation of the j-th factor.
- the contribution of the i-th variable in% to the formation of the j-th factor.
The sum of the squares of all factor loadings in a row is equal to one, the total variance of one variable, and all factors for all variables is equal to the total variance (i.e., the trace or order of the correlation matrix, or the sum of its eigenvalues)  .
.
In general, the factorial structure of the i-th feature is presented in the form  , which includes only significant loads. Using the factorial loadings matrix, it is possible to calculate the values \u200b\u200bof all factors for each observation of the original sample population by the formula:
, which includes only significant loads. Using the factorial loadings matrix, it is possible to calculate the values \u200b\u200bof all factors for each observation of the original sample population by the formula:
 ,
,
where  - the value of the j-th factor in the t-th observation,
- the value of the j-th factor in the t-th observation,  -standardized value of the i-th feature in the t-th observation of the original sample;
-standardized value of the i-th feature in the t-th observation of the original sample;  –Factor load,
–Factor load,  –The intrinsic value corresponding to the factor j. These calculated values
–The intrinsic value corresponding to the factor j. These calculated values  are widely used for graphical presentation of the results of factor analysis.
are widely used for graphical presentation of the results of factor analysis.
The correlation matrix can be restored from the factor loadings matrix:  .
.
The part of the variance of a variable explained by the principal components is called the generality.
 ,
,
where  is the variable number, and
is the variable number, and  -number of the main component. The correlation coefficients reconstructed only for the main components will be less than the original ones in absolute value, and on the diagonal there will be not 1, but the values \u200b\u200bof the communities.
-number of the main component. The correlation coefficients reconstructed only for the main components will be less than the original ones in absolute value, and on the diagonal there will be not 1, but the values \u200b\u200bof the communities.
Specific contribution  -th main component is determined by the formula
-th main component is determined by the formula
 .
.
The total contribution of the  principal components are determined from the expression
principal components are determined from the expression
 .
.
Usually used for analysis  the first principal components, whose contribution to the total variance exceeds 60-70%.
the first principal components, whose contribution to the total variance exceeds 60-70%.
The factor loadings matrix A is used for the interpretation of principal components, and usually those values \u200b\u200bthat exceed 0.5 are considered.
Principal component values \u200b\u200bare given by the matrix

Principal component method (PCA - Principal component analysis) is one of the main ways to reduce the dimension of data with the least loss of information. Invented in 1901 by Karl Pearson, it is widely used in many fields. For example, for data compression, "computer vision", recognition of visible patterns, etc. The calculation of the principal components is reduced to the calculation of the eigenvectors and eigenvalues \u200b\u200bof the covariance matrix of the initial data. Principal component analysis is often called karhunen-Loewe transformation (Karhunen-Loeve transform) or hotelling transformation (Hotelling transform). The mathematicians Kosambi (1943), Pugachev (1953) and Obukhova (1954) also worked on this issue.
The main component analysis task aims to approximate (approximate) data with linear manifolds of lower dimension; find subspaces of lower dimension, in the orthogonal projection on which the spread of the data (that is, the standard deviation from the mean) is maximum; find subspaces of lower dimension, in the orthogonal projection to which the root-mean-square distance between points is maximum. In this case, one operates with finite data sets. They are equivalent and do not use any hypothesis about statistical data generation.
In addition, the task of principal component analysis may be the goal of constructing for a given multidimensional random variable such an orthogonal transformation of coordinates that, as a result of the correlation between individual coordinates, will turn to zero. This version operates with random variables.
Fig. 3
The above figure shows the points Pi on the plane, p i - the distance from Pi to line AB. Looking for a straight line AB that minimizes the sum
The principal component method began with the problem of the best approximation (approximation) of a finite set of points by straight lines and planes. For example, given a finite set of vectors. For each k \u003d 0,1, ..., n? 1 among all k-dimensional linear manifolds in find such that the sum of the squares of the deviations x i from L k is minimal:
where? Euclidean distance from a point to a linear manifold.
Any k-dimensional linear manifold in can be specified as a set of linear combinations, where the parameters in i run through the real line, and? orthonormal set of vectors
where is the Euclidean norm,? Euclidean dot product, or in coordinate form:
Solution of the approximation problem for k \u003d 0,1, ..., n? 1 is given by a set of embedded linear manifolds
These linear manifolds are defined by an orthonormal set of vectors (vectors of principal components) and a vector a 0. The vector a 0 is sought as a solution to the minimization problem for L 0:


The result is a sample mean:
French mathematician Maurice Fréchet Fréchet Maurice Réné (09/02/1878 - 06/04/1973) is an outstanding French mathematician. He worked in the field of topology and functional analysis, probability theory. The author of modern concepts of metric space, compactness and completeness. Auth. in 1948, noticed that the variational definition of the mean, as a point that minimizes the sum of the squares of the distances to data points, is very convenient for constructing statistics in an arbitrary metric space, and built a generalization of classical statistics for general spaces, called the generalized least squares method.
Principal component vectors can be found as solutions to the same type of optimization problems:
1) centralize the data (subtract the average):
2) we find the first principal component as a solution to the problem;

3) Subtract the projection onto the first main component from the data:
4) we find the second principal component as a solution to the problem

If the solution is not unique, then we choose one of them.
2k-1) Subtract the projection onto the (k? 1) th principal component (recall that the projections to the previous (k? 2) principal components have already been subtracted):
2k) we find the kth principal component as a solution to the problem:

If the solution is not unique, then we choose one of them.

Figure: 4
The first principal component maximizes the sample variance of the data projection.
For example, let's say we are given a centered set of data vectors where the arithmetic mean of x i is zero. Task? find such an orthogonal transformation to a new coordinate system for which the following conditions would be true:
1. The sample dispersion of data along the first coordinate (principal component) is maximal;
2. The sample dispersion of the data along the second coordinate (second principal component) is maximal if it is orthogonally to the first coordinate;
3. The sample dispersion of the data along the values \u200b\u200bof the k-th coordinate is maximum, provided that the first k is orthogonal? 1 coordinates;
The sample variance of the data along the direction given by the normalized vector a k is
(since the data is centered, the sample variance here is the mean square of the deviation from zero).
The solution to the problem of the best approximation gives the same set of principal components as the search for orthogonal projections with the largest scattering, for a very simple reason:
and the first term does not depend on a k.
The transformation matrix of the data to principal components is constructed from the vectors "A" of the principal components:
Here a i - orthonormal column vectors of the principal components, arranged in descending order of eigenvalues, the superscript T means transposition. Matrix A is orthogonal: AA T \u003d 1.
After transformation, most of the data variation will be concentrated in the first coordinates, which makes it possible to discard the rest and consider the space of reduced dimension.
The oldest principal component selection method is kaiser's rule, Kaiser Johann Henrich Gustav (16.03.1853, Brezno, Prussia - 14.10.1940, Germany) - an outstanding German mathematician, physicist, researcher in the field of spectral analysis. Auth. by which those main components are significant for which
that is, l i is greater than the mean of l (the mean sample variance of the coordinates of the data vector). The Kaiser rule works well in simple cases when there are several principal components with l i much larger than the mean, and the rest of the eigenvalues \u200b\u200bare less than it. In more complex cases, it can give too many significant principal components. If the data are normalized to a unit sample variance along the axes, then the Kaiser rule takes on an especially simple form: only those principal components are significant for which l i\u003e 1.
One of the most popular heuristic approaches to estimating the number of principal components required is broken cane rule, when the set of eigenvalues \u200b\u200bnormalized to the unit sum (, i \u003d 1, ... n) is compared with the distribution of the lengths of fragments of a cane of unit length broken in n? 1st randomly selected point (break points are chosen independently and are equally distributed along the length of the cane). If L i (i \u003d 1, ... n) are the lengths of the obtained cane pieces, numbered in descending order of length:, then the mathematical expectation of L i:

Let's look at an example that involves estimating the number of principal components using the broken cane rule in dimension 5.

Figure: five.
According to the broken cane rule, the kth eigenvector (in descending order of eigenvalues \u200b\u200bl i) is stored in the list of principal components if
The figure above is an example for the 5-dimensional case:
l 1 \u003d (1 + 1/2 + 1/3 + 1/4 + 1/5) / 5; l 2 \u003d (1/2 + 1/3 + 1/4 + 1/5) / 5; l 3 \u003d (1/3 + 1/4 + 1/5) / 5;
l 4 \u003d (1/4 + 1/5) / 5; l 5 \u003d (1/5) / 5.
For example, selected
0.5; =0.3; =0.1; =0.06; =0.04.
According to the broken cane rule, in this example, 2 main components should be left:
It should only be borne in mind that the broken cane rule tends to underestimate the number of significant principal components.
After projection onto the first k principal components with, it is convenient to normalize to the unit (sample) variance along the axes. The variance along the ith principal component is equal to), therefore, for normalization, the corresponding coordinate must be divided by. This transformation is not orthogonal and does not preserve the dot product. The covariance matrix of the data projection after normalization becomes unit, the projections to any two orthogonal directions become independent quantities, and any orthonormal basis becomes the basis of the principal components (recall that normalization changes the vector orthogonality ratio). The mapping from the space of the initial data to the first k principal components together with the normalization is given by the matrix

It is this transformation that is most often called the Karhunen-Loeve transformation, that is, the main component method itself. Here a i are column vectors, and the superscript T means transposition.
In statistics, when using the principal component analysis, several technical terms are used.
Data matrix , where each row is a vector of preprocessed data (centered and correctly normalized), the number of rows is m (the number of data vectors), the number of columns is n (the dimension of the data space);
Load matrix (Loadings), where each column is a principal component vector, the number of rows is n (dimension of the data space), the number of columns is k (the number of principal component vectors selected for projection);
Account Matrix (Scores)
where each row is the projection of the data vector onto k principal components; number of rows - m (number of data vectors), number of columns - k (number of vectors of principal components selected for projection);
Z-score matrix (Z-scores)

where each row is the projection of the data vector onto k principal components, normalized to the unit sample variance; number of rows - m (number of data vectors), number of columns - k (number of vectors of principal components selected for projection);
Error matrix (leftovers) (Errors or residuals)
Basic formula:
Thus, the Principal Component Method is one of the main methods of mathematical statistics. Its main purpose is to distinguish between the need to study data sets with a minimum of their use.
In an effort to accurately describe the area of \u200b\u200binterest, analysts often select a large number of independent variables (p). In this case, a serious error can occur: several descriptive variables can characterize the same side of the dependent variable and, as a result, highly correlate with each other. The multicollinearity of the independent variables seriously distorts the research results, so it should be eliminated.
Principal component analysis (as a simplified factor analysis model, since this method does not use individual factors describing only one variable x i) allows you to combine the influence of highly correlated variables into one factor characterizing the dependent variable from one side. As a result of the analysis carried out by the method of principal components, we will achieve the compression of information to the required size, the description of the dependent variable m (m First, you need to decide how many factors you need to highlight in this study. Within the framework of the method of principal components, the first main factor describes the largest percentage of variance of independent variables, then - in decreasing order. Thus, each successive main component, identified sequentially, explains a smaller proportion of the variability of factors x i. The challenge for the researcher is to determine when the variability becomes truly small and random. In other words, how many principal components should be selected for further analysis. There are several methods for the rational selection of the required number of factors. The most used of these is the Kaiser test. According to this criterion, only those factors are selected whose eigenvalues \u200b\u200bare greater than 1. Thus, a factor that does not explain the variance, equivalent to at least the variance of one variable, is omitted. Let's analyze Table 19 built in SPSS: Table 19. Total variance explained As can be seen from Table 19, in this study, the xi variables are highly correlated with each other (this was also revealed earlier and can be seen from Table 5 “Pairwise correlation coefficients”), and therefore, characterize the dependent variable Y from almost one side: initially, the first principal component explains 90 , 7% of the variance xi, and only the eigenvalue corresponding to the first principal component is greater than 1. Of course, this is a drawback of data selection, but this drawback was not obvious in the selection process itself. Analysis in the SPSS package allows you to independently select the number of principal components. Let's choose the number 6 - equal to the number of independent variables. The second column of Table 19 shows the sum of the squares of the rotational loads, and it is from these results that we draw a conclusion about the number of factors. The eigenvalues \u200b\u200bcorresponding to the first two principal components are greater than 1 (55.246% and 38.396%, respectively), therefore, according to the Kaiser method, we will single out the 2 most significant principal components. The second method for identifying the required number of factors is the “scree” criterion. According to this method, the eigenvalues \u200b\u200bare presented in the form of a simple graph, and a place on the graph is selected where the decrease of the eigenvalues \u200b\u200bfrom left to right slows down as much as possible: Figure 3. Scree criterion As can be seen in Figure 3, the decay of the eigenvalues \u200b\u200bslows down from the second component, but the constant rate of decay (very small) starts only from the third component. Therefore, the first two principal components will be selected for further analysis. This conclusion is consistent with the conclusion obtained using the Kaiser method. Thus, the first two successively obtained principal components are finally selected. After identifying the main components that will be used in further analysis, it is necessary to determine the correlation of the initial variables x i with the obtained factors and, based on this, give names to the components. For the analysis, we will use the factor loadings matrix A, the elements of which are the coefficients of correlation of factors with the original independent variables: Table 20. Factor loadings matrix In this case, the interpretation of the correlation coefficients is difficult, therefore, it is rather difficult to name the first two main components. Therefore, further we will use the Varimax method of orthogonal rotation of the coordinate system, the purpose of which is to rotate the factors so as to choose the simplest factor structure for interpretation: Table 21. Coefficients of interpretation From Table 21 it can be seen that the first principal component is most associated with the variables x1, x2, x3; and the second one with variables x4, x5, x6. Thus, we can conclude that investment in fixed assets in the region (variable Y) depends on two factors: - the volume of own and borrowed funds received by the enterprises of the region for the period (first component, z1); -
as well as the intensity of investments of regional enterprises in financial assets and the amount of foreign capital in the region (second component, z2). Figure 4. Scatter diagram This diagram shows disappointing results. At the very beginning of the study, we tried to select the data so that the resulting variable Y was distributed normally, and we practically succeeded. The distribution laws of the independent variables were quite far from normal, but we tried to bring them as close as possible to the normal law (to select the data accordingly). Figure 4 shows that the initial hypothesis about the closeness of the law of distribution of independent variables to the normal law is not confirmed: the shape of the cloud should resemble an ellipse, in the center, objects should be located more densely than at the edges. It is worth noting that making a multidimensional sample in which all the variables are distributed according to the normal law is a task that can be performed with great difficulty (moreover, it does not always have a solution). However, this goal should be pursued: then the results of the analysis will be more meaningful and understandable for interpretation. Unfortunately, in our case, when most of the work on analyzing the collected data has been done, it is rather difficult to change the sample. But further, in subsequent works, it is worth taking a more serious approach in the sample of independent variables and maximally approximating the law of their distribution to the normal one. The last stage of the principal component analysis is the construction of a regression equation for the principal components (in this case, for the first and second principal components). Using SPSS, we calculate the parameters of the regression model: Table 22. Parameters of the regression equation for principal components The regression equation will take the form: y \u003d 47 414.184 + 0.916 * z1 + 0.213 * z2, (b0) (b1) (b2) t. about. b0=47 414,184
shows the point of intersection of the regression line with the axis of the resulting indicator; b1 \u003d 0.916 -with an increase in the value of the factor z1 by 1, the expected average value of the amount of investment in fixed assets will increase by 0.916; b2 \u003d 0.213 -with an increase in the value of the factor z2 by 1, the expected average value of the amount of investment in fixed assets will increase by 0.213. In this case, the value of tcr ("alpha" \u003d 0.001, "nu" \u003d 53) \u003d 3.46 is less than tobl for all "beta" coefficients. Therefore, all coefficients are significant. Table 24. Quality of the regression model for principal components Table 24 reflects indicators that characterize the quality of the constructed model, namely: R - multiple k-t correlation - indicates what proportion of the variance Y is explained by the variation in Z; R ^ 2 - to-t determination - shows the proportion of the explained variance of deviations of Y from its mean value. The standard error of the estimate characterizes the error of the constructed model. Let us compare these indicators with similar indicators of the power-law regression model (its quality turned out to be higher than the quality of the linear model, so we compare it with the power-law model): Table 25. Quality of power regression model So, multiple k-t correlation R and k-t determination R ^ 2 in the power model is slightly higher than in the principal component model. In addition, the standard error of the principal component model is MUCH higher than that of the power law. Therefore, the quality of a power-law regression model is higher than a regression model based on principal components. Let us verify the regression model of the main components, i.e., analyze its significance. Let's check the hypothesis about the insignificance of the model, calculate F (obs.) \u003d 204.784 (calculated in SPSS), F (crit) (0.001; 2; 53) \u003d 7.76. F (obs)\u003e F (crit), therefore, the hypothesis that the model is insignificant is rejected. The model is meaningful. So, as a result of the component analysis, it was found that from the selected independent variables xi, 2 main components can be distinguished - z1 and z2, and z1 is more influenced by the variables x1, x2, x3, and z2 - x4, x5, x6 ... The regression equation based on the principal components turned out to be significant, although it is inferior in quality to the power regression equation. According to the regression equation for principal components, Y positively depends on both Z1 and Z2. However, the initial multicollinearity of the variables xi and the fact that they are not distributed according to the normal distribution law can distort the results of the constructed model and make it less significant. Cluster Analysis The next stage of this research is cluster analysis. The task of cluster analysis is to divide the selected regions (n \u200b\u200b\u003d 56) into a relatively small number of groups (clusters) based on their natural proximity with respect to the values \u200b\u200bof the variables x i. When conducting cluster analysis, we assume that the geometric proximity of two or more points in space means the physical proximity of the corresponding objects, their homogeneity (in our case, the homogeneity of the regions in terms of indicators affecting investments in fixed assets). At the first stage of cluster analysis, it is necessary to determine the optimal number of allocated clusters. To do this, it is necessary to carry out hierarchical clustering - the sequential combination of objects into clusters until there are two large clusters, which are combined into one at the maximum distance from each other. The result of hierarchical analysis (conclusion about the optimal number of clusters) depends on the method of calculating the distance between clusters. Thus, we will test various methods and draw appropriate conclusions. Nearest Neighbor Method If we calculate the distance between individual objects in a unified way - as a simple Euclidean distance - the distance between clusters is calculated by different methods. According to the "nearest neighbor" method, the distance between clusters corresponds to the minimum distance between two objects of different clusters. The analysis in the SPSS package is as follows. First, the matrix of distances between all objects is calculated, and then, based on the matrix of distances, the objects are sequentially combined into clusters (for each step, the matrix is \u200b\u200bcompiled anew). The steps for sequential combining are presented in the table: Table 26. Steps of agglomeration. Nearest Neighbor Method As can be seen from Table 26, at the first stage, elements 7 and 8 were combined, since the distance between them was minimal - 0.003. Further, the distance between the combined objects increases. The table also shows the optimal number of clusters. To do this, you need to look after which step there is a sharp jump in the distance, and subtract the number of this agglomeration from the number of objects under study. In our case: (56-53) \u003d 3 is the optimal number of clusters. Figure 5. Dendrogram. Nearest Neighbor Method A similar conclusion about the optimal number of clusters can be made by looking at the dendrogram (Fig. 5): you should select 3 clusters, and the first cluster will include objects numbered 1-54 (54 objects in total), and the second and third clusters - one object each (numbered 55 and 56, respectively). This result suggests that the first 54 regions are relatively homogeneous in terms of indicators affecting investments in fixed assets, while objects numbered 55 (Republic of Dagestan) and 56 (Novosibirsk region) stand out significantly against the general background. It is worth noting that these entities have the largest investment in fixed assets among all the selected regions. This fact once again proves the high dependence of the resulting variable (investment volume) on the selected independent variables. Similar reasoning is carried out for other methods of calculating the distance between clusters. Distant Neighbor Method Table 27. Agglomeration steps. Distant Neighbor Method In the far neighbor method, the distance between clusters is calculated as the maximum distance between two objects in two different clusters. According to Table 27, the optimal number of clusters is (56-53) \u003d 3. Figure 6. Dendrogram. Distant Neighbor Method According to the dendrogram, the optimal solution would also be to select 3 clusters: the first cluster will include regions numbered 1-50 (50 regions), the second - 51-55 (5 regions), and the third - the last region numbered 56. Center of gravity method In the method of "center of gravity" the distance between clusters is the Euclidean distance between the "centers of gravity" of clusters - the arithmetic mean of their indices x i. Figure 7. Dendrogram. Center of gravity method Figure 7 shows that the optimal number of clusters is as follows: 1 cluster - 1-47 objects; 2 cluster - 48-54 objects (6 in total); 3 cluster - 55 objects; 4 cluster - 56 objects. Medium bond principle In this case, the distance between clusters is equal to the average value of the distances between all possible pairs of observations, with one observation taken from one cluster, and the second, respectively, from the other. Analysis of the agglomeration steps table showed that the optimal number of clusters is (56-52) \u003d 4. Let us compare this conclusion with the conclusion obtained from the analysis of the dendrogram. Figure 8 shows that cluster 1 will include objects numbered 1-50, cluster 2 - objects 51-54 (4 objects), cluster 3 - region 55, cluster 4 - region 56. Figure 8. Dendrogram. Medium bond method Principal component method Principal component method (eng. Principal component analysis, PCA
) is one of the main ways to reduce the dimension of data, losing the least amount of information. Invented by K. Pearson (eng. Karl pearson
) in d. It is used in many fields, such as pattern recognition, computer vision, data compression, etc. The calculation of the principal components is reduced to the calculation of eigenvectors and eigenvalues \u200b\u200bof the covariance matrix of the initial data. The principal component method is sometimes called karhunen-Loeve transformation (eng. Karhunen-loeve) or Hotelling transformation (eng. Hotelling transform). Other ways to reduce the dimension of data are the method of independent components, multidimensional scaling, as well as numerous nonlinear generalizations: the method of principal curves and manifolds, the method of elastic maps, finding the best projection (eng. Projection pursuit), neural network methods "bottleneck", etc. The principal component analysis problem has at least four basic versions: The first three versions operate on finite data sets. They are equivalent and do not use any hypothesis about statistical data generation. The fourth version operates with random variables. Finite sets appear here as samples from a given distribution, and the solution of the first three problems as an approximation to the "true" Karhunen-Loeve transformation. This raises an additional and not completely trivial question about the accuracy of this approximation. Illustration for the famous work of K. Pearson (1901): given points on a plane, - the distance from to a straight line. Looking for a straight line that minimizes the amount The principal component method began with the problem of the best approximation of a finite set of points by lines and planes (K. Pearson, 1901). A finite set of vectors is given. For each, among all -dimensional linear manifolds in, find such that the sum of the squares of the deviations from is minimal: where is the Euclidean distance from a point to a linear manifold. Any -dimensional linear manifold in can be specified as a set of linear combinations, where the parameters run through the real line, and is an orthonormal set of vectors where is the Euclidean norm, is the Euclidean scalar product, or in coordinate form: The solution to the approximation problem for is given by a set of embedded linear manifolds,. These linear manifolds are defined by an orthonormal set of vectors (vectors of principal components) and a vector. The vector is sought as a solution to the minimization problem for: Principal component vectors can be found as solutions to the same type of optimization problems: 1) centralize the data (subtract the average):. Now ; 2) we find the first principal component as a solution to the problem; ... If the solution is not unique, then we choose one of them. 3) Subtract from the data the projection onto the first main component:; 4) find the second principal component as a solution to the problem. If the solution is not unique, then we choose one of them. … 2k-1) Subtract the projection onto the -th principal component (recall that the projections onto the previous principal components have already been subtracted):; 2k) we find the kth principal component as a solution to the problem:. If the solution is not unique, then we choose one of them. ... At each preparatory step, subtract the projection onto the previous principal component. The found vectors are orthonormal simply as a result of solving the described optimization problem, however, in order to prevent computation errors from violating the mutual orthogonality of the vectors of the principal components, they can be included in the conditions of the optimization problem. Non-uniqueness in the definition, apart from the trivial arbitrariness in the choice of the sign (and they solve the same problem), can be more essential and occur, for example, from the conditions of data symmetry. The last principal component is a unit vector orthogonal to all previous ones. The first principal component maximizes the sample variance of the data projection Let's say we are given a centered set of data vectors (the arithmetic mean is zero). The task is to find such an orthogonal transformation to a new coordinate system, for which the following conditions would be true: The theory of singular value decomposition was created by J.J. Sylvester (eng. James joseph sylvester
) in G. and is presented in all the detailed manuals on matrix theory. The main procedure is to find the best approximation of an arbitrary matrix by a matrix of the form (where is a -dimensional vector, and - is a -dimensional vector) by the least squares method: The solution to this problem is given by successive iterations using explicit formulas. For a fixed vector, the values \u200b\u200bthat give the minimum to the form are uniquely and explicitly determined from the equalities: Similarly, for a fixed vector, the values \u200b\u200bare determined: As an initial approximation of the vector, we take a random vector of unit length, calculate the vector, then calculate the vector for this vector, etc. Each step decreases the value. As a stopping criterion, the smallness of the relative decrease in the value of the minimized functional per iteration step () or the smallness of the value itself is used. As a result, the best approximation was obtained for the matrix by the matrix of the form (here the superscript denotes the approximation number). Further, we subtract the resulting matrix from the matrix, and for the resulting deviation matrix, we again seek the best approximation of the same type, etc., until, for example, the norm becomes sufficiently small. As a result, we got an iterative procedure for decomposing a matrix in the form of a sum of matrices of rank 1, that is. We assume and normalize vectors: As a result, an approximation of singular numbers and singular vectors (right - and left -) is obtained. The advantages of this algorithm include its exceptional simplicity and the ability to transfer it to data with spaces, as well as weighted data, almost unchanged. There are various modifications to the basic algorithm to improve accuracy and stability. For example, the vectors of the principal components for different ones should be orthogonal "by construction", however, with a large number of iterations (large dimension, many components), small deviations from orthogonality accumulate and a special correction may be required at each step, ensuring its orthogonality to the previously found principal components. Often a data vector has the additional structure of a rectangular table (for example, a flat image) or even a multidimensional table - that is, a tensor:,. In this case, it is also effective to use the singular value decomposition. The definition, basic formulas and algorithms are carried over practically unchanged: instead of the data matrix, we have the -index value, where the first index is the number of the data point (tensor). The main procedure is to find the best approximation of a tensor by a tensor of the form (where is the -dimensional vector (is the number of data points), is the vector of dimension at) by the least squares method: The solution to this problem is given by successive iterations using explicit formulas. If all the vectors-factors are given except one, then this remaining one is determined explicitly from the sufficient minimum conditions. As an initial approximation of vectors (), we take random vectors of unit length, calculate a vector, then for this vector and these vectors, calculate a vector, etc. (cyclically iterating over the indices) Each step decreases the value. The algorithm obviously converges. As a stopping criterion, the smallness of the relative decrease in the value of the minimized functional per cycle or the smallness of the value itself is used. Further, we subtract the obtained approximation from the tensor and for the remainder we again look for the best approximation of the same type, etc., until, for example, the norm of the next remainder becomes sufficiently small. This multicomponent singular value decomposition (tensor principal component method) is successfully used in the processing of images, video signals, and, more broadly, any data that has a tabular or tensor structure. The transformation matrix of data to principal components consists of vectors of principal components arranged in descending order of eigenvalues: That is, the matrix is \u200b\u200borthogonal. Most of the data variation will be concentrated in the first coordinates, which allows moving to a space of lower dimensions. Let the data be centered,. When replacing data vectors with their projection onto the first principal components, the mean square of the error is introduced per one data vector: where the eigenvalues \u200b\u200bof the empirical covariance matrix, arranged in descending order, taking into account the multiplicity. This quantity is called residual variance... The quantity called explained variance... Their sum is equal to the sample variance. The corresponding squared relative error is the ratio of residual variance to sample variance (i.e. proportion of unexplained variance): By the relative error, the applicability of the principal component method with projection onto the first components is estimated. Comment: in most computational algorithms, the eigenvalues \u200b\u200bwith the corresponding eigenvectors - the principal components are calculated in the order "from large to smallest". To calculate, it is enough to calculate the first eigenvalues \u200b\u200band the trace of the empirical covariance matrix, (the sum of the diagonal elements, that is, the variances along the axes). Then The target approach to estimating the number of principal components based on the required fraction of the explained variance is formally always applicable, but implicitly it assumes that there is no separation into “signal” and “noise”, and any predetermined accuracy makes sense. Therefore, a different heuristic based on the hypothesis of the presence of a “signal” (relatively small dimension, relatively large amplitude) and “noise” (large dimension, relatively small amplitude) is often more productive. From this point of view, the principal component method works like a filter: the signal is contained mainly in the projection onto the first principal components, and in the remaining components the proportion of noise is much higher. Question: how to estimate the number of required principal components if the signal-to-noise ratio is not known in advance? The simplest and oldest method for selecting principal components gives kaiser's rule (eng. Kaiser "s rule): those main components are significant for which that is, it exceeds the mean (mean sample variance of the coordinates of the data vector). The Kaiser rule works well in simple cases when there are several principal components with much higher than the mean, and the rest of the eigenvalues \u200b\u200bare less than it. In more complex cases, it can give too many significant principal components. If the data are normalized to a unit sample variance along the axes, then the Kaiser rule takes on an especially simple form: only those principal components are significant for which Example: Estimating the number of principal components by the broken cane rule in dimension 5. One of the most popular heuristic approaches to estimating the number of principal components required is broken cane rule (eng. Broken stick model). The set of eigenvalues \u200b\u200bnormalized to the unit sum (,) is compared with the distribution of the lengths of the fragments of the reed of unit length broken at the th randomly selected point (the break points are chosen independently and are equally distributed along the length of the reed). Let () be the lengths of the obtained cane pieces, numbered in descending order of length:. It is not hard to find the mathematical expectation: According to the broken cane rule, the th eigenvector (in descending eigenvalue order) is stored in the list of principal components if In Fig. an example is given for the 5-dimensional case: For example, selected According to the broken cane rule, in this example, 2 main components should be left: According to user estimates, the broken cane rule tends to underestimate the number of significant principal components. After of projection onto the first principal components with, it is convenient to normalize to the unit (sample) dispersion along the axes. The variance along the x principal component is equal to), therefore, for normalization, it is necessary to divide the corresponding coordinate by. This transformation is not orthogonal and does not preserve the dot product. The covariance matrix of the data projection after normalization becomes unit, the projections to any two orthogonal directions become independent quantities, and any orthonormal basis becomes the basis of the principal components (recall that normalization changes the vector orthogonality ratio). The mapping from the original data space to the first principal components, together with normalization, is given by the matrix It is this transformation that is most often called the Karhunen-Loeve transformation. Here are column vectors and superscript means transpose. Warning: one should not confuse the normalization carried out after the transformation to the main components with the normalization and "dimensionlessization" at data preprocessingcarried out before calculating the principal components. Preliminary normalization is needed for a reasonable choice of the metric in which the best approximation of the data will be calculated, or the directions of the greatest scatter will be sought (which is equivalent). For example, if the data are three-dimensional vectors of "meters, liters and kilogram", then using the standard Euclidean distance, a difference of 1 meter in the first coordinate will make the same contribution as a difference of 1 liter in the second, or 1 kg in the third ... Usually, the systems of units in which the initial data are presented do not accurately reflect our ideas about the natural scales along the axes, and “dimensionlessization” is carried out: each coordinate is divided into a certain scale determined by the data, the purposes of their processing and the measurement and data collection processes. There are three essentially different standard approaches to such a normalization: unit variance along the axes (scales along the axes are equal to the mean square deviations - after this transformation, the covariance matrix coincides with the matrix of correlation coefficients), on equal measurement accuracy (the scale along the axis is proportional to the measurement accuracy of this value) and on equal claims in the problem (the scale along the axis is determined by the required forecast accuracy of a given value or its permissible distortion - the level of tolerance). The choice of preprocessing is influenced by the meaningful formulation of the problem, as well as the conditions for data collection (for example, if the data collection is fundamentally incomplete and the data will still arrive, then it is irrational to choose the normalization strictly to unit variance, even if this corresponds to the meaning of the problem, since this implies renormalization of all data after receiving a new portion; it is wiser to choose a certain scale that roughly estimates the standard deviation, and then not change it). Pre-normalization to unit dispersion along the axes is destroyed by rotating the coordinate system if the axes are not principal components, and normalization during data preprocessing does not replace normalization after reduction to principal components. If we associate each data vector with a unit mass, then the empirical covariance matrix will coincide with the inertia tensor of this system of point masses (divided by the total mass), and the problem of principal components - with the problem of reducing the tensor of inertia to the principal axes. Additional freedom in the choice of mass values \u200b\u200bcan be used to account for the importance of data points or the reliability of their values \u200b\u200b(larger masses are assigned to important data or data from more reliable sources). If the data vector is given mass, then instead of the empirical covariance matrix we get All further operations to reduce to principal components are performed in the same way as in the basic version of the method: we look for an orthonormal eigenbasis, arrange it in descending order of eigenvalues, estimate the weighted average error of approximating the data by the first components (by the sums of eigenvalues), normalize, etc. ... A more general weighing method gives maximizing the weighted sum of pairwise distances between projections. For every two data points, a weight is entered; and. Instead of the empirical covariance matrix, use For, the symmetric matrix is \u200b\u200bpositive definite, since the quadratic form is positive: Next, we look for an orthonormal proper basis, order it in descending order of eigenvalues, estimate the weighted average error of approximating the data by the first components, etc. - exactly as in the main algorithm. This method is applied if there are classes: for different classes, the weight is chosen to be larger than for points of the same class. As a result, in the projection onto the weighed principal components, different classes are "moved apart" to a greater distance. Another application is reducing the influence of large deviations (outlays, eng. Outlier
), which can distort the picture due to the use of the rms distance: if selected, the effect of large deviations will be reduced. Thus, the described modification of the principal component method is more robust than the classical one. In statistics, when using the principal component analysis, several technical terms are used. Data matrix ; each row is a vector pre-processed data ( centered and right normalized), number of rows - (number of data vectors), number of columns - (dimension of data space); Load matrix (Loadings); each column is a vector of principal components, the number of rows is (dimension of the data space), the number of columns is (the number of vectors of principal components selected for projection); Account Matrix (Scores); each row is the projection of the data vector onto the principal components; number of rows - (number of data vectors), number of columns - (number of principal component vectors selected for projection); Z-score matrix (Z-scores); each row is the projection of the data vector onto the principal components, normalized to the unit sample variance; number of rows - (number of data vectors), number of columns - (number of principal component vectors selected for projection); Error matrix (or leftovers) (Errors or residuals). Basic formula: Principal component analysis is always applicable. The widespread statement that it is applicable only to normally distributed data (or for distributions close to normal) is incorrect: in the original formulation of K. Pearson, the problem is posed about approximations a finite set of data, and there is not even a hypothesis about their statistical generation, not to mention the distribution. However, the method does not always effectively reduce the dimension under the given accuracy constraints. Lines and planes do not always provide a good approximation. For example, the data can follow a curve with good accuracy, and that curve can be difficult to position in the data space. In this case, the principal component analysis will require several components (instead of one) for acceptable accuracy, or will not give a reduction in dimension at all with acceptable accuracy. To work with such "curves" of principal components, the method of principal manifolds and various versions of the nonlinear method of principal components were invented. Data with complex topology can be more troublesome. Various methods have also been invented to approximate them, such as self-organizing Kohonen maps, neural gas, or topological grammars. If the data is statistically generated with a distribution that is very different from the normal, then to approximate the distribution it is useful to go from the principal components to independent components that are no longer orthogonal in the original dot product. Finally, for an isotropic distribution (even normal), instead of a scattering ellipsoid, we obtain a ball, and it is impossible to reduce the dimension by approximation methods. Data visualization - the presentation in a visual form of experimental data or the results of a theoretical study. The first choice in visualizing a dataset is to orthogonal projection onto the plane of the first two principal components (or 3-dimensional space of the first three principal components). The design plane is essentially a flat, two-dimensional "screen" positioned to provide a "picture" of the data with the least amount of distortion. Such a projection will be optimal (among all orthogonal projections onto different two-dimensional screens) in three respects: Data visualization is one of the most widely used applications of principal component analysis and its nonlinear generalizations. To reduce the spatial redundancy of pixels when coding images and video, linear transformations of blocks of pixels are used. Subsequent quantization of the obtained coefficients and lossless coding allow obtaining significant compression ratios. Using the PCA transform as a linear transform is optimal for some types of data in terms of the size of the obtained data with the same distortion. At the moment, this method is not actively used, mainly due to the great computational complexity. Also, data compression can be achieved by discarding the last conversion factors. Principal component analysis is one of the main methods in chemometrics (eng. Chemometrics
). Allows to divide the matrix of initial data X into two parts: "meaningful" and "noise". By the most popular definition, "Chemometrics is a chemical discipline that uses mathematical, statistical and other methods based on formal logic to construct or select optimal measurement methods and experimental designs, and to extract the most important information in the analysis of experimental data." In political science, the principal component method was the main tool of the Political Atlas of Modernity project for linear and nonlinear analysis of the ratings of 192 countries of the world according to five specially developed integral indices (living standards, international influence, threats, statehood and democracy). For the cartography of the results of this analysis, a special GIS (Geographic Information System) has been developed, combining the geographic space with the feature space. Political atlas data maps have also been created using the two-dimensional principal manifolds in the five-dimensional space of countries as a substrate. The difference between a data map and a geographic map is that on a geographic map there are objects that have similar geographic coordinates nearby, while on a data map there are objects (countries) with similar attributes (indices) nearby.
Component Initial eigenvalues Sums of squares of rotational loads
Total % Dispersion Cumulative% Total % Dispersion Cumulative%
dimension0
5,442
90,700
90,700
3,315
55,246
55,246
,457
7,616
98,316
2,304
38,396
93,641
,082
1,372
99,688
,360
6,005
99,646
,009
,153
99,841
,011
,176
99,823
,007
,115
99,956
,006
,107
99,930
,003
,044
100,000
,004
,070
100,000
Isolation method: Principal component analysis.
Component matrix a
Component
X1 ,956
-,273
,084
,037
-,049
,015
X2 ,986
-,138
,035
-,080
,006
,013
X3 ,963
-,260
,034
,031
,060
-,010
X4 ,977
,203
,052
-,009
-,023
-,040
X5 ,966
,016
-,258
,008
-,008
,002
X6 ,861
,504
,060
,018
,016
,023
Isolation method: Principal component analysis.
a. Extracted components: 6
Rotated component matrix a
Component
X1 ,911
,384
,137
-,021
,055
,015
X2 ,841
,498
,190
,097
,000
,007
X3 ,900
,390
,183
-,016
-,058
-,002
X4 ,622
,761
,174
,022
,009
,060
X5 ,678
,564
,472
,007
,001
,005
X6 ,348
,927
,139
,001
-,004
-,016
Isolation method: Principal component analysis. Rotation method: Varimax with Kaiser normalization.
a. The rotation converged in 4 iterations.

Model Unstandardized odds Standardized odds t Znch.
B Std. Error Beta
(Constant) 47414,184
1354,505
35,005
,001
Z1 26940,937
1366,763
,916
19,711
,001
Z2 6267,159
1366,763
,213
4,585
,001
Model R R-square Adjusted R-squared Std. estimation error
dimension0
, 941 a ,885
,881
10136,18468
a. Predictors: (const) Z1, Z2
b. Dependent Variable: Y
Stage The cluster is merged with Odds Next stage
Cluster 1 Cluster 2 Cluster 1 Cluster 2
,003
,004
,004
,005
,005
,005
,005
,006
,007
,007
,009
,010
,010
,010
,010
,011
,012
,012
,012
,012
,012
,013
,014
,014
,014
,014
,015
,015
,016
,017
,018
,018
,019
,019
,020
,021
,021
,022
,024
,025
,027
,030
,033
,034
,042
,052
,074
,101
,103
,126
,163
,198
,208
,583
1,072

Stage The cluster is merged with Odds Stage of the first appearance of the cluster Next stage
Cluster 1 Cluster 2 Cluster 1 Cluster 2
,003
,004
,004
,005
,005
,005
,005
,007
,009
,010
,010
,011
,011
,012
,012
,014
,014
,014
,017
,017
,018
,018
,019
,021
,022
,026
,026
,027
,034
,035
,035
,037
,037
,042
,044
,046
,063
,077
,082
,101
,105
,117
,126
,134
,142
,187
,265
,269
,275
,439
,504
,794
,902
1,673
2,449



Formal problem statement
Fitting data with linear manifolds
Finding Orthogonal Projections with the Most Scattering

Simple iterative singular value decomposition algorithm
Singular value decomposition and tensor principal component method
Conversion matrix to principal components
Residual variance
Selection of principal components according to the Kaiser rule
Estimation of the number of principal components by the broken cane rule

Normalization
Normalization after reduction to principal components
Normalization before calculating principal components
Mechanical analogy and principal component analysis for weighted data
Special terminology
Limits of applicability and limitations of the effectiveness of the method
Examples of using
Data visualization
Compression of images and videos
Reducing noise in images
Chemometrics
Psychodiagnostics
- Dried fruit sweets "Energy koloboks"
- Raspberries grated with sugar: tasty and healthy
- Alexey Pleshcheev: biography
- How to preserve apple juice
- Cabbage salad with carrots like in a dining room - the best recipes from childhood
- An even complexion without foundation!
- Pumpkin juice with carrots for the winter